- ▶데이터 인프라 (1/2) : 전체적인 맥락 (OLAP와 OLTP, 데이터웨어하우스(DW),ETL,ODS 등등)
- 데이터 인프라 (2/2) : 우리회사의 데이터 인프라 (회사관련내용이라 포스팅하진 않으나 나중에 참고용으로 남겨둡니다)
큰 시스템에서 데이터가 흐르는 조직이 되려면, 다양한 데이터를 분석하려면 데이터 인프라가 잘 구축되어있어야한다.
데이터 인프라를 구축하려면 DB만 있으면 되는게 아니고 다양한 기술과 여러가지 솔루션, 오픈소스, saas등이 엮여서 구축되는거다.
정말 다양하고 복잡한데, 아래 도표에 대해서 이해하는거를 목표로 공부 했다.
아래 내용을 이해함에 있어 위 도표(Unified Data Infrastructure (2.0)를 계속 참고하면서 보길 바랍니당.
아래건 2020년도버전
- 간단설명 : 소스에서 가져온 데이터를 변환하고 적재, 분석해서 보여준다가 데이터 인프라에서 하는 일임.
1. source : 회사 내에 모든 데이터가 만들어지는곳
2. Ingestion and transformation : 데이터를 가져와서 변환하는곳
3. Stroage : 스토리지
4. Query and Proceesing : 들어온 데이터 분석 및 예측 (머신러닝)
5. Analysis and Output : 분석된 결과를 보여주는 곳
😄데이터 인프라의 목적
(분석시스템) 비즈니스 리더들의 의사결정을 도와주기
(운영시스템) 서비스 / 제품을 데이터의 도움을 받아 향상시키기
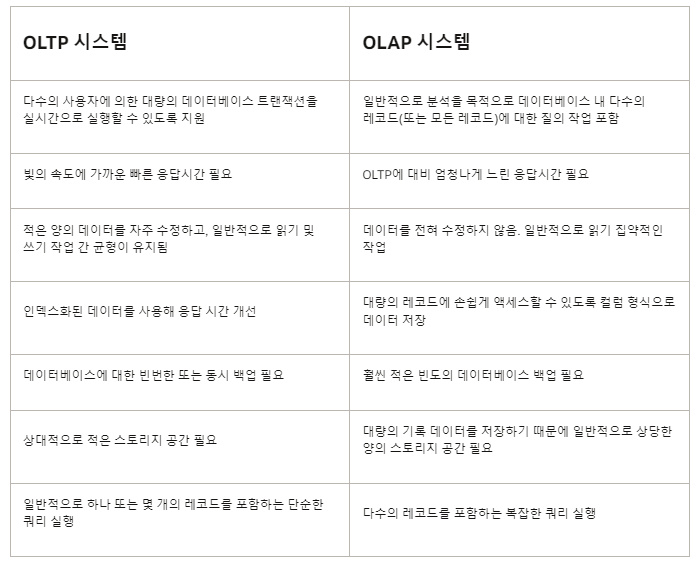
😄Production System (Source) VS DW(Stroage~query and processing) VS DL(Stroage~query and processing)
Production System
ERP, CRM(ex salesforce), DB 등등 원천 데이터를 저장하는 시스템으로 시스템마다 모두 시스템에 맞게 정의된 방식으로 저장하고 있어 모두 다 다른 형태임.
데이터를 정규화해서 가지고 있음 (다양한 테이블이 존재)
Data Warehouse
통합된 보고서 작성을 위해 다양한 소스로 부터 추출(E),변환(T) 과정을 거친 데이터가 있는곳
다차원(Dimensional) 데이터 모델을 사용함(우린 스타스키마 사용 중)
통계용 데이터가 필요하기때문에 일반적인 DB 데이터와 저장방식이 다름(많은 계산을 요구하는 Join을 피하기 위함)